Your context engineering isn’t an implementation detail. It’s the whole product. Most AI products feel like wrappers because their prompts, retrieval, and evals deliver basic capability. The ones that don’t feel like wrappers are maximizing what the model can do.
Compare these prompts:
Basic: “Write a professional email to doctors about our diabetes drug.”
Maximizing: “Write an email to HCPs about [DRUG] for Type 2 diabetes. Subject line: max 10 words, include primary efficacy endpoint. Body: 3 paragraphs. P1: Clinical results from [STUDY] with citation [1]. P2: Safety profile, include required disclaimer. P3: Clear outcome driven CTA. Tone: evidence-based, align with FDA promotional guidelines. Flag any claim that lacks direct label support.”
The first delivers inconsistent output needing heavy editing. The second ships.
Most teams can’t tell you where they stand. Start here: track how often outputs ship without human editing. Basic teams are editing 60%+ of outputs. Maximizing teams edit less than 20%. The gap is calibration.
This is compound calibration: improvements that propagate across your product (horizontal) and multiply with each model upgrade (vertical). Fix one prompt pattern and every workflow using it improves — if twenty workflows share it, that’s 20x leverage. When the next model ships, your calibrated system extracts more from the upgrade. If competitors get a 10% improvement from a new model, you get 20%. After five releases, you’re 3x ahead. That’s why it compounds — normal product improvements are local, these are systemic.
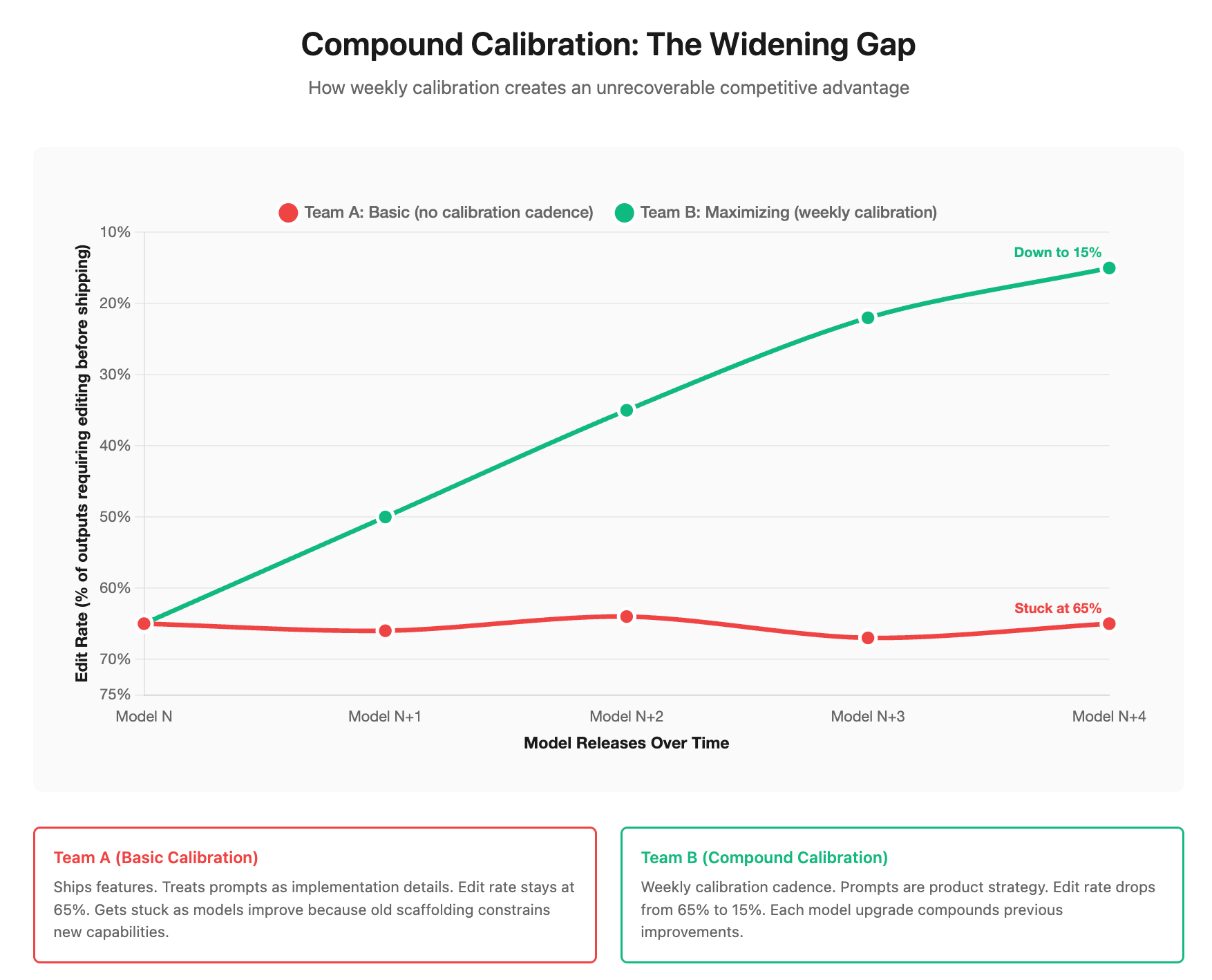
Here’s what stops most teams: they don’t track edit/intervention rates, prompts are scattered across the codebase, calibration looks like “polishing” compared to “shipping features,” and no one owns it. Product delegates to eng. Eng treats prompts as implementation. No one can systematically improve what no one is measuring.
The moat is teams that are empowered to calibrate on cadence. Every week, asking: How can we improve what we put in the context window? What needs to fight to stay? What scaffolding can fall away? What needs to be added in? Prompt reviews are the new design reviews. Every day is day 0.
Product leaders should own this. In AI, model capabilities determine product possibilities. You can’t define strategy without understanding the capabilities and limitations of the model you’re using. And you can’t understand what they can do without staying close to the metal. Start simple: pick your highest-volume workflow, track edit rates in a spreadsheet for 100 outputs, rewrite the prompt with explicit structure, measure improvement. Put this on a cycle. Two hours weekly — review edit rates, test one improvement, ship, and measure.
When the next model releases: Run your eval set on both models. Look for scaffolding that’s now obsolete, capabilities you can now add, and what needs tightening. Delete what’s irrelevant, tighten what stays, incorporate to meet the new model’s needs. Measure whether edit rates drop.
Most AI products stay at basic because calibration isn’t a cadence but is treated as a one-time task during initial build. The ones that maximize treat calibration as continuous strategy. Every other moat is copyable. This one requires making calibration a discipline.